Downstream Control Tasks Results
The DecisionNCE encoders are pretrained using large-scale human video dataset EpicKitchen. We freeze the pretrained vision-language encoders and use their output representations as input to a 256-256 MLP to train LCBC policies.
Results on Real Robots

Figure 1: Real robot LCBC experimental results. Success rate is averaged over 10 episodes and 3 seeds.
Red cup on silver pan
Red cup on red plate
Duck on green plate
Duck in pot
Move pot
Fold cloth
Flip the red cup upright
Open the microwave
Close the microwave
Results on Simulation
We also evaluate on the FrankaKitchen benchmark. We train LCBC policies on 5 tasks in FrankaKitchen environment using 1/3/5 demonstrations for each task. DecisionNCE achieves the highest success rate across diverse dataset quantities, demonstrating its effectiveness in extracting valuable information from out-of-domain data.
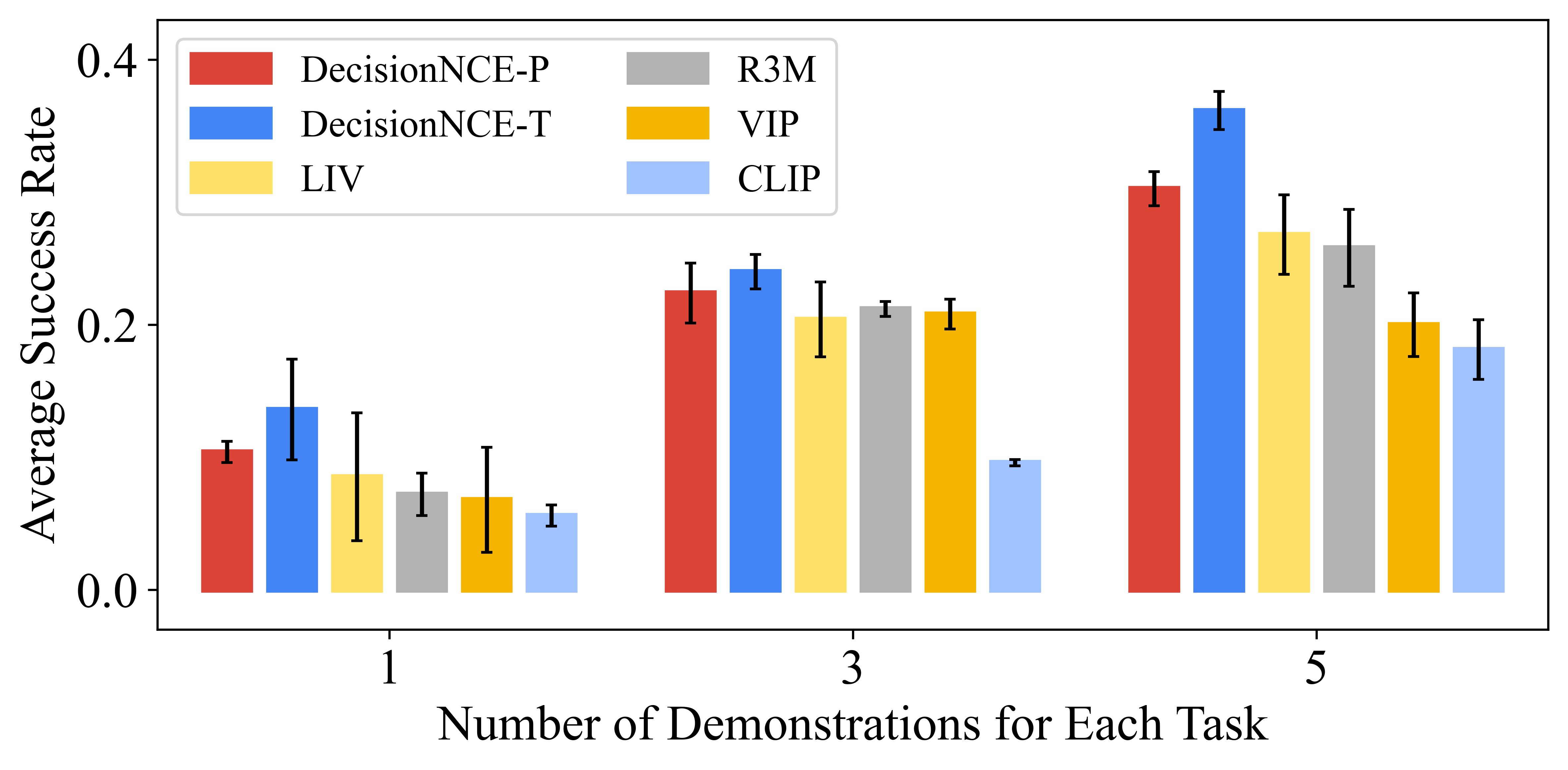
Figure 2: Simulation LCBC results. Max success rate averaged over 25 evaluation episodes and 3 seeds.





BibTeX
@inproceedings{lidecisionnce,
title={DecisionNCE: Embodied Multimodal Representations via Implicit Preference Learning},
author={Li, Jianxiong and Zheng, Jinliang and Zheng, Yinan and Mao, Liyuan and Hu, Xiao and Cheng, Sijie and Niu, Haoyi and Liu, Jihao and Liu, Yu and Liu, Jingjing and others},
booktitle={Forty-first International Conference on Machine Learning}
}